
| AI Research Intern @ RTE France | 03/24 - 07/24 | Paris, FR |






During my research internship at RTE, France’s electricity transmission system operator, I was embedded within the Data Science and Artificial Intelligence (DS-AI) team. The primary challenge was to enhance RTE’s strategic monitoring capabilities by developing advanced methods to automatically process and analyze massive volumes of textual data from news and social media.
The Challenge: Detecting Emerging Trends and Weak Signals
RTE operates over 100,000 km of critical electrical infrastructure and must stay ahead of emerging trends, risks, and technological advancements. These can range from new decarbonization technologies and evolving energy policies to security risks like ecological protests near facilities. Manually sifting through the daily deluge of information is inefficient and risks missing early, subtle indicators—or “weak signals”—that could later have a significant impact. The goal was to create a system that could automatically identify these nascent trends and track their evolution over time.
The Solution: BERTrend
To address this, I developed BERTrend, a novel framework for detecting and monitoring emerging trends in large, evolving text corpora. BERTrend leverages the power of neural topic modeling in an online learning setting to dynamically identify and classify topics.
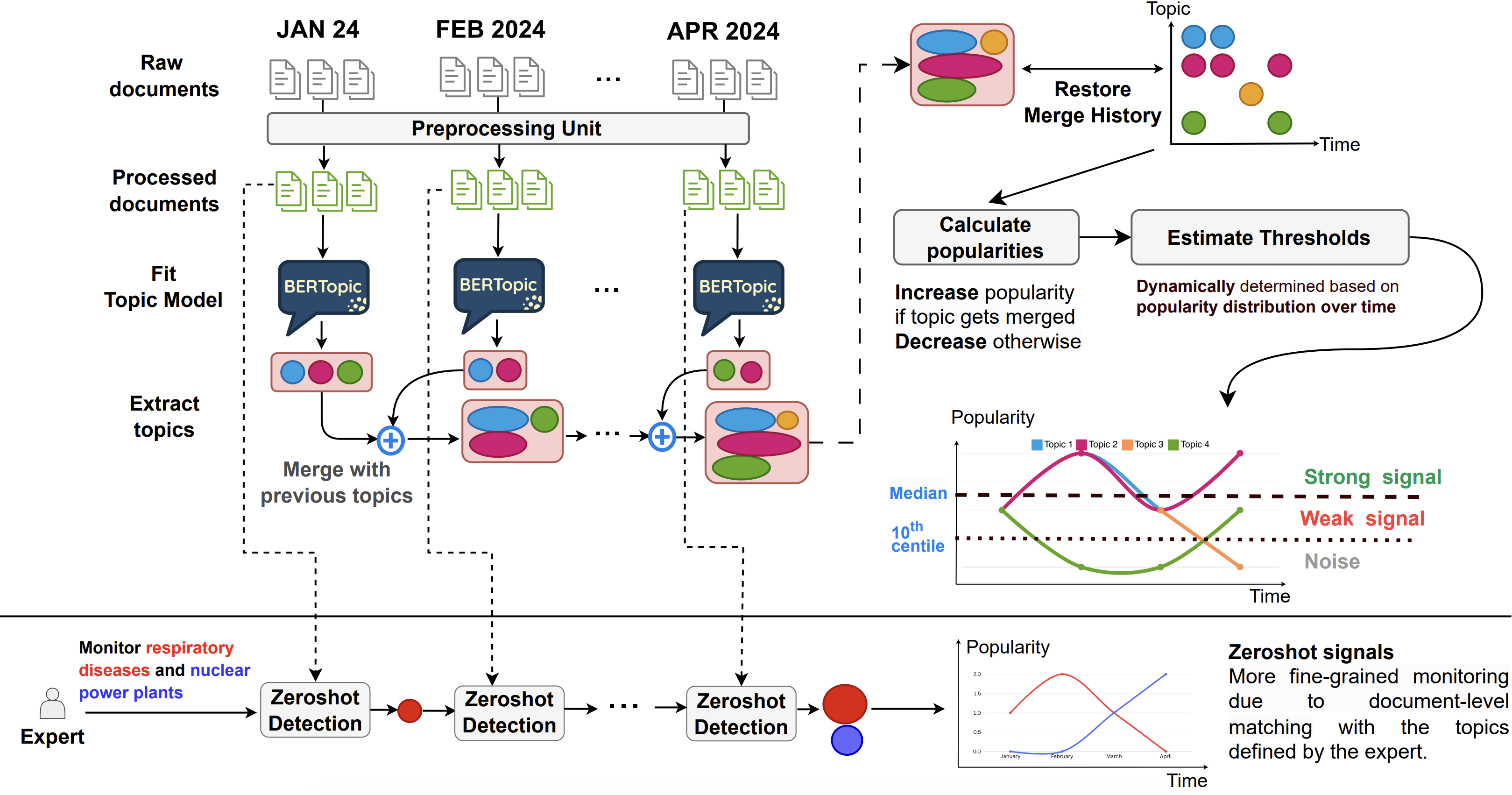
The core methodology is as follows:
- Neural Topic Modeling: At its heart, BERTrend uses BERTopic, a state-of-the-art topic modeling technique. It processes incoming documents in time-based batches (e.g., daily or weekly). For each batch, it uses the
all-mpnet-base-v2sentence transformer to generate contextual document embeddings. - Clustering and Topic Creation: The high-dimensional embeddings are first reduced using UMAP and then clustered with HDBSCAN. This allows for the discovery of semantically coherent topics without pre-specifying the number of clusters.
- Dynamic Topic Tracking: To track topics over time, models from consecutive time slices are merged. Topics are linked based on the cosine similarity of their embeddings, allowing us to follow a single conceptual theme as it evolves.
- Popularity and Signal Classification: A key innovation is a dynamic popularity metric that accounts for both the number of documents in a topic and its update frequency. Topics that are not updated decay in popularity exponentially. Based on this score, topics are classified using dynamic thresholds (the 10th and 50th percentiles over a rolling window) into three categories:
- Noise: Low-popularity, irrelevant topics.
- Weak Signal: Topics with low-to-moderate popularity but a clear upward trend, indicating potential emergence.
- Strong Signal: High-popularity, well-established topics.
- Zero-Shot Monitoring: The framework also includes a feature for experts to monitor specific, predefined areas of interest (e.g., “respiratory diseases” or “nuclear power plant security”) with high sensitivity, catching relevant documents even if they don’t form a distinct cluster on their own.
Key Achievements
- Developed and Deployed a Working Prototype: A fully functional prototype of BERTrend was built using Streamlit and deployed internally at RTE. This tool allowed experts in the territorial coordination and security departments to validate the detected signals, confirming that the system could identify important topics that were previously overlooked by manual monitoring.
- Published Research Paper: The methodology and findings were consolidated into a research paper, “BERTrend: Neural Topic Modeling for Emerging Trends Detection,” which was accepted for publication at the EMNLP 2024 FuturED workshop.
- Open-Sourced Code: To foster further research and collaboration, the complete codebase for BERTrend, including visualization and analysis tools, was made publicly available on GitHub: https://github.com/rte-france/BERTrend.
Tools and Technologies
- Programming Language: Python
- Core Libraries: PyTorch, Hugging Face (Transformers, Datasets), BERTopic, UMAP, HDBSCAN
- Prototyping & Visualization: Streamlit, Plotly
- Data: The model was validated on large-scale datasets, including news articles (The New York Times) and scientific papers (arXiv).